Postgres checkpoints and how to tune them
3 years ago
Table of contents
Checkpoint configuration in Postgres feels like hidden knowledge, but it's arguably the second most important part of configuring your database (behind shared_buffers).
Recently, we had a series of incidents stemming from instability around request times and database load. After a lot of digging, we found that there's a whole lot of configuration PostgreSQL expects around its checkpointing. After tweaking the values explained here, our database became much healthier, and our request times even improved by 10%!
This blog post aims to simplify the various configuration options available, and when to use them.
Background knowledge
When changes are made to a postgres database, they’re stored in the write-ahead log (WAL). Eventually, the WAL will be chunked and synced to the database’s disk. Checkpoints will then run periodically to write the chunked WALs back into the database. Until then, queries will have to check all non-checkpointed WALs in addition to the database itself for new transactions.
This means that upon a crash, the database will load up its state as of the latest checkpoint, then it will replay all of the transactions in the WAL.
How you can tell you have a problem
There are some things you can do to monitor for a problem. To name a few:
- Monitor your CheckpointLag. If it's not dropping with a consistent cadence to a consistent value, something might be off
- Check your postgres logs
- Search for "checkpoint complete"
- These logs contain some important details:
- how many WAL files are being added, removed, and recycled
- how long writes, syncs, and full checkpoints take
- the amount of data written in the checkpoint
- If your values for "distance" and "estimate" are pretty far off, you likely have an issue
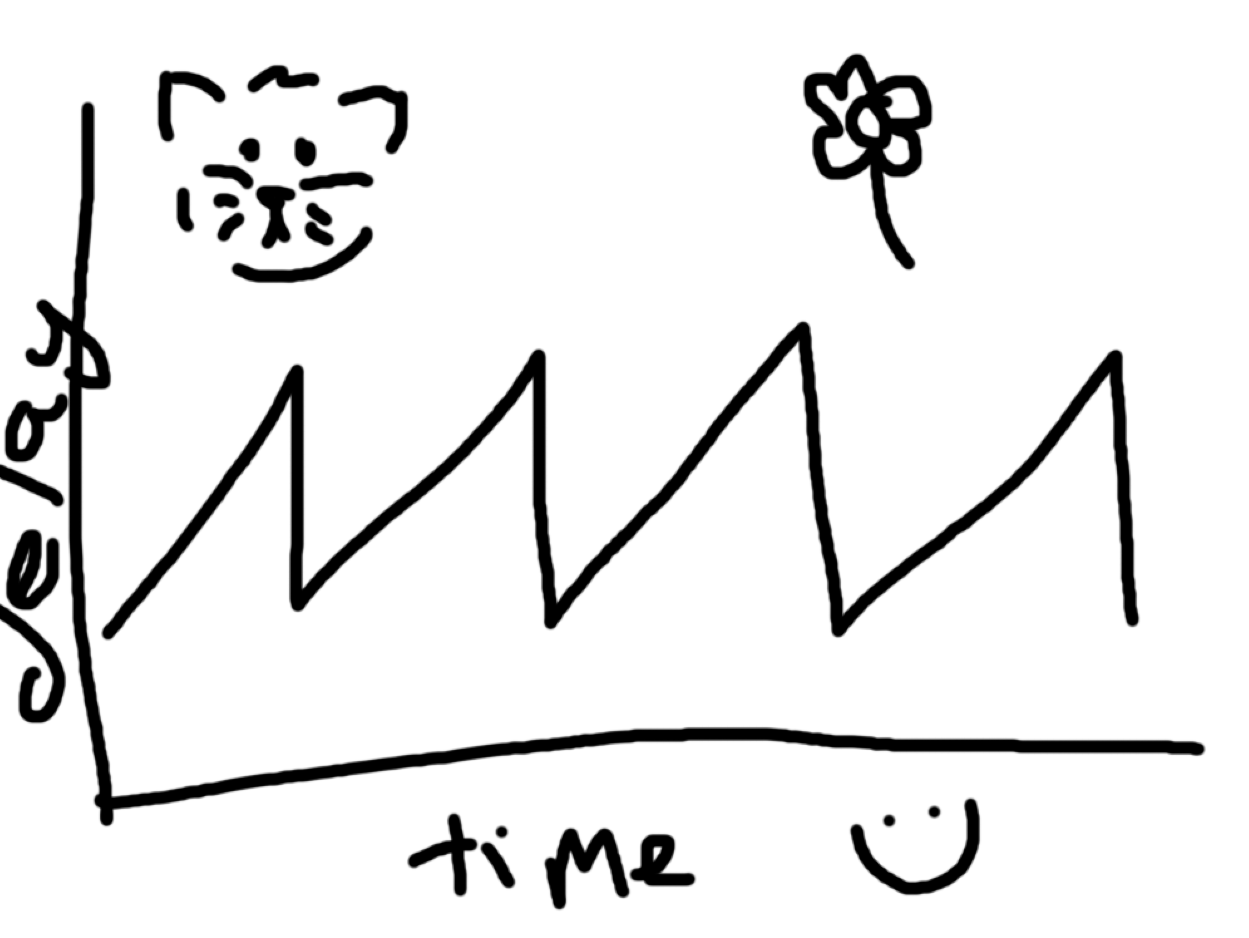 What a healthy checkpoint lag over time graph should look like
What a healthy checkpoint lag over time graph should look likeTo start, full_page_writes should be on in just about any case. That’s not what this blog post is about but you can read why here.
See how bad the issue is
Checkpoints are run periodically (the frequency of requested checkpoints is defined by checkpoint_timeout), and when they complete in time and the next one naturally begins it’s considered a timed checkpoint. If checkpoints are calculating too slow or out of tune, they will be requested checkpoints.
Requested checkpoints are almost always bad, and should only occur occasionally with very high load. You can see information about how many of each there are with this query:
So if there’s a substantial amount of requested checkpoints and they’re continuing to increase, it’s time to tune.
max_wal_size
max_wal_size is considered the most important config to tune out of the ones in this document. The value is a file size. When the WAL reaches the max_wal_size, a checkpoint will be requested. A checkpoint being requested is generally bad, because it will cause unexpected and unpredictable strain on the database.
max_wal_size should be kept as high as possible, with the tradeoff of disk usage. Of course as we increase the max size, the storage we use on our database’s machine will increase with it. If it can be afforded, many large systems will use tens or hundreds of gigabytes for their max wal size.
checkpoint_timeout and checkpoint_completion_target
Increasing the max_wal_size is safe to do because we have checkpoint_timeouts. Checkpoint timeout tells postgres how often a checkpoint should be triggered. This pairs with checkpoint_completion_target, which is a percentage (like 0.8) that tells postgres “allocate your resources to checkpointing such that the checkpoint write finishes in 80% of the checkpoint timeout”. So, for example, with a 15 minute checkpoint timeout and 0.8 completion target, healthy checkpoints will tend to write in about 12 minutes (15*0.8).
Note that the checkpoint write is not the only thing that needs to happen. If you look at your checkpoint complete logs, you’ll see:
So, there’s some write time (in this example, we had 0.9 completion target and 10 minute checkpoint timeout, hence ~540s write). But there’s also sync time, and some small unknown factor contributing to the total. So, keep your checkpoint_completion_target low enough to provide time for these other operations. Keep your checkpoint_timeout at a number where you’re checkpointing frequently enough to keep checkpoints manageable in size, while not checkpointing so often it hogs database resources.
min_wal_size
min_wal_size is set to a size on disk. As long as the WAL disk usage stays below the amount, the old WAL files will be recycled for use at checkpoints, rather than removed. Recycling a WAL file means it is renamed to become future a future segment in the numbered sequence.
Recycling WALs (from increasing min_wal_size) will reduce checkpoint calculation time (generally in the “sync” step) and resources used during checkpoints.
While the "write" step is throttled, the "sync" step is not. This means that if your syncs are too much for your IO or other resources to handle, each checkpoint's sync can cause disruption in your database. Increasing your min_wal_size to encourage recycling and faster syncs can prevent some serious app degradation (which is what we experienced).
Note that min_wal_size and max_wal_size have nothing to do with each other. min_wal_size determines how much WAL to minimally keep between checkpoints, and max_wal_size dictates how much WAL we should have before a checkpoint should be requested.
wal_buffers
It’s unlikely that wal_buffers will end up relevant, but it determines how much shared memory should be used for WAL data that hasn’t been written to disk. From the official postgres docs:
”The contents of the WAL buffers are written out to disk at every transaction commit, so extremely large values are unlikely to provide a significant benefit. However, setting this value to at least a few megabytes can improve write performance on a busy server where many clients are committing at once. The auto-tuning selected by the default setting of -1 should give reasonable results in most cases.”
Preventative care
These kinds of issues can be hard to see coming. When you Google things like "prevent issues scaling postgres", the results give tons of great advice about indexing, sharding, etc.. but not about the boring stuff like this.
Unfortunately we can't tell the future and it's expensive to scale preemptively, but there's a few things you can check to see if your checkpoints are in a danger zone:
- Look at your checkpoint complete logs. If the
distanceof your biggest checkpoints is creeping up to yourmax_wal_size(80% or more), you should increase it - To test how your checkpoints would perform with increased load, you can simulate it by reducing your
checkpoint_complete_target. If you cut it in half, the database will try to complete the writes twice as fast. Unfortunately, this doesn't test the impact of the unthrottled sync step. - Share your learnings with your team. You can turn an all-nighter incident extravaganza into a quick fix if everybody is at least aware that these options exist. We don't have to memorize much in our field, but we do need to keep pointers in our brain to the information we need, so even awareness is enough.
External resources
Long-winded discussion about experimentation around this
Comments
No comments yet.